

Dashboard de Normalidade
Olá 😀!
Este artigo tem como objetivo descrever os métodos utilizados para desenvolver o Dashboard de avaliação da Normalidade de um conjunto de dados. Saber se um conjunto de dados segue, pelo menos aproximadamente, a distribuição Normal, impacta no tipo de estatísticas que podem ser aplicadas no conjunto de dados.
Índice
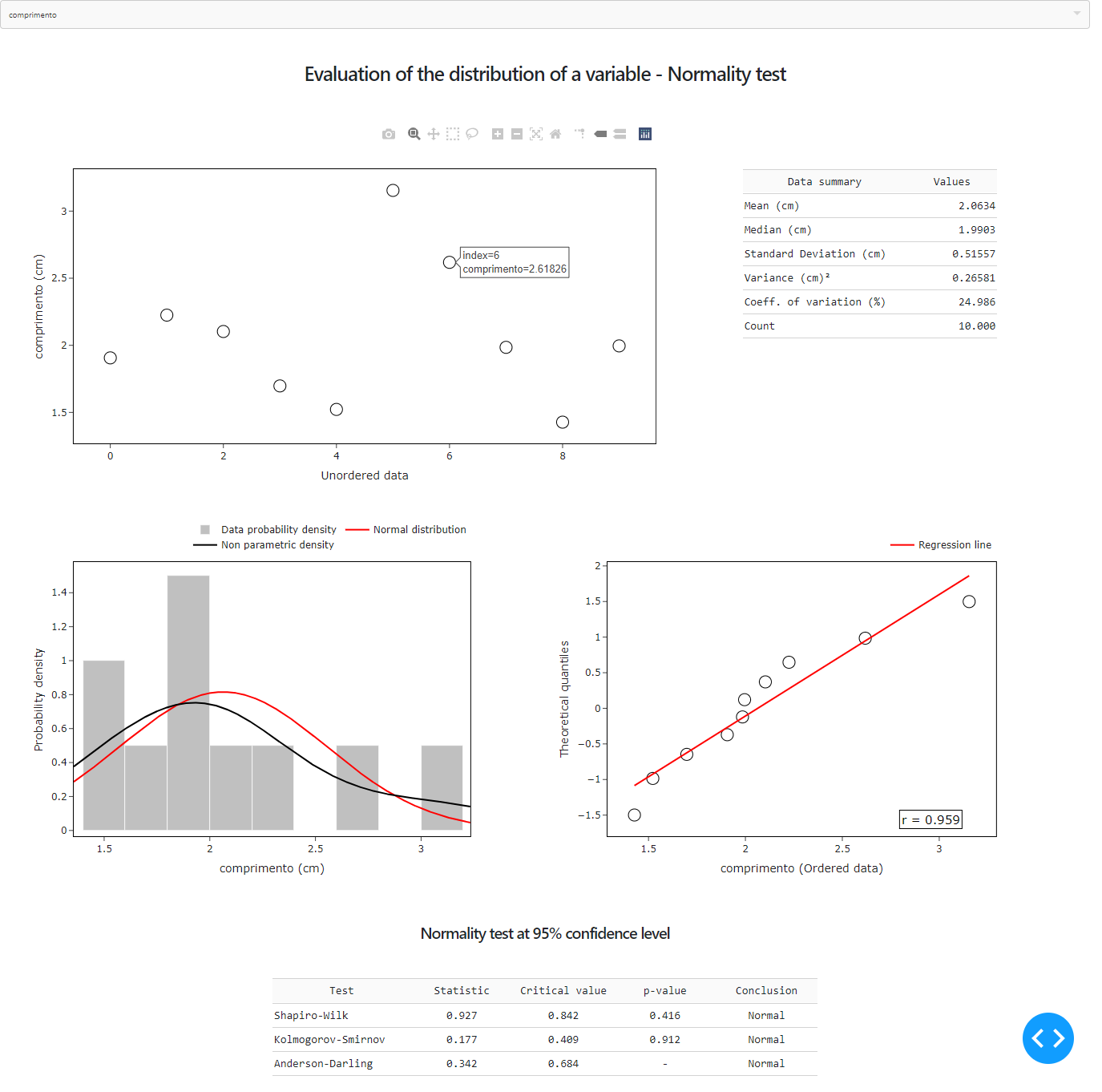
O Dashboard finalizado tem esta aparência (estático):
Figura 1 - Dashboard finalizado.
Introdução
Este Dashbard foi desenvolvido para ser utilizado no google.colab. Esta plataforma é um ambiente de Jupyter Notebooks gratuito que roda na nuvem e armazena seus notebooks no Google Drive. Dessa forma, é necessário ter uma conta no Google para poder utilizar este Dashboard.
Para rodar o Dashboard, basta clicar neste link e seguir o passo a passo descrito.
A partir da entrada de um conjunto de dados, é gerado tabelas e gráficos interativos, que facilitam a interpretação dos resultados. São gerados:
-
Gráfico de dispersão interativo;
-
Tabela com as principais métricas de avaliação de uma amostra (média, mediana, desvio padrão, etc);
-
Histograma de probabilidade interativo com a distribuição paramétrica (Normal) e distribuição não paramétrica;
-
QQ-plot interativo;
-
Tabela com os testes de Normalidade de Shapiro-Wilk, Anderson-Darling e Kolmogorov-Smirnov;
Bibliotecas utilizadas
Para rodar este Dashboard foram utilizadas as seguintes bibliotecas:
✔ Pandas (para gerenciar os dados);
✔ NumPy (cálculos);
✔ SciPy (análise estatística);
✔ Plotly (para gerar gráficos interativos);
✔ Dash (para gerar Dashboards interativos);
✔ Dash Bootstrap Components (para utilizar BOOTSTRAP);
De qualquer forma, o script desenvolvido irá automaticamente baixar e instalar todas as bibliotecas necessárias, e você não precisa se preocupar com esta etapa.
Conjunto de dados base
O conjunto de dados base (ou padrão) foi obtido no Portal Action, onde podem ser facilmente validados quanto a todas as informações geradas nesse Dashboard.
Gráfico de dispersão
Para desenhar o gráfico de dispersão foi utilizado o plotly.express.scatter(), com os valores fornecidos pelo usuário no eixo y e com a respectiva ordem numérica dos dados no eixo x (o primeiro elemento está na posição 0). Caso o usuário passe a unidade dos dados, ela será adiciona junto ao nome dos dados no título do eixo y.
Tabela de estatísticas básicas
Ao lado do gráfico de dispersão, uma tabela será desenhada contendo as principais métricas de avaliação de um conjunto de dados. São elas:
- Média: utilizando o método
np.mean();
\(\bar{x} = \frac{\sum_{i=1}^n x_{i} }{n}\) (1)
onde \(x_{i}\) é o valor de cada medida independente que foi obtida e (\(n\)) é o número total de observações.
-
Mediana: utilizando o método
np.median() -
Desvio padrão: utilizando o método
np.std(ddof=1). O desvio padrão é calculado admitindo dados amostrais;
\(s = \sqrt{\frac{\sum_{i=1}^n(x_{i}-\bar{x})^2 }{n-1} }\) (2)
- Variância: utilizando o método
np.var(ddof=1). A variância é calculada admitindo dados amostrais;
\(s^{2} = \frac{\sum_{i=1}^n(x_{i}-\bar{x})^2 }{n-1}\) (3)
- Coeficiente de variação: calculado utilizando a seguinte equação:
\(CV(\%) = \frac{100\times s}{\bar{x}} \) (4)
- Contagem: número total de amostras presentes no conjunto de dados (número experimental);
O número de casas decimais apresentado depende no número de casas decimais do conjunto de dados original.
Histograma
O histograma dos dados é desenhado utilizando o plotly.express.histogram(), utilizando o número de colunas igual a 10 e com o parâmetro histnorm='probability density', o que gera o gráfico de densidade de probabilidade.
Neste gráfico é adicionado os valores esperados para a distribuição Normal, que são obtidos utilizando stats.norm.pdf() com a média e o desvio padrão do conjunto de dados. A distribuição Normal esperada é plotada adicionando um traço de plotly.graph_objs.Scatter() na figura do histograma.
Também é adicionado densidade não paramétrica para o conjunto de dados, sendo estimada utilizando o método stats.gaussian_kde(). A densidade não paramétrica é adicionada através de um traço de plotly.graph_objs.Scatter() na figura do histograma.
QQ-plot
Os valores teóricos do qq-plot são calculados utilizando o método stats.probplot(dist="norm"), sendo plotados no eixo y. No eixo x, são plotados os valores originais ordenados de forma crescente. O gráfico é desenhado utilizando o plotly.express.scatter().
Para auxiliar na interpretação dos resultados, uma linha de regressão é adicionada no gráfico. A regressão linear é feita utilizando o scipy.stats.linregress(). A linha obtida é adicionada no gráfico como um traço utilizando o plotly.graph_objs.Scatter().
Também é adicionado o valor do coeficiente de Pearson no canto inferior direito do QQ-plot, através de uma anotação.
Tabela de Normalidade
Ao final do Dashboard é apresentada uma tabela com o resultado dos testes de Shapiro-Wilk, Anderson-Darling e Kolmogorov-Smirnov, com uma conclusão clara do resultado dos testes. Todos os testes são concluídos utilizando 5% de significância. Para selecionar várias células ao mesmo tempo, clique em cima de uma célula e selecione as linhas/colunas utilizando o teclado (Shift + setas). Após seleção, copie e cole utilizando Ctrl+C e Ctrl+V, respectivamente.
Teste de Shapiro-Wilk
- Teste de Shapiro-Wilk:
Este teste é aplicado utilizando o
scipy.stats.shapiro(), retornando a estatística do teste, o valor tabelado, o p-valor e a conclusão baseada no valor de p. Mais detalhes sobre o teste de Shapiro-Wilk neste texto ou neste vídeo.
Teste de Kolmogorov-Sminorv
- Teste de Kolmogorov-Smirnov:
Este teste é aplicado utilizando o
scipy.stats.kstest(cdf='norm'), retornando a estatística do teste, o valor tabelado, o p-valor e a conclusão baseada no valor de p. Mais detalhes sobre o teste de Kolmogorov-Smirnov neste vídeo.
Teste de Anderson-Darling
- Teste de Anderson-Darling:
Este teste é aplicado utilizando o
scipy.stats.anderson('norm'), retornando a estatística do teste, o valor tabelado, e a conclusão baseada no valor na comparação entre a estatística e o valor tabelado. Mais detalhes sobre o teste de Anderson-Darling aqui.
Conclusão
Verificar se um conjunto de dados segue a distribuição Normal nunca foi tão simples. Basta apenas entrar com os seus dados, e pronto. Várias formas de avaliar são apresentadas de forma simples e clara. Dashboards assim são muito promissores.
Dashboards interativos são uma ferramenta muito interessante para a visualização de dados, e ajuda muito na intepretação de resultados. Desenvolve-los não é tão difícil quanto parece quanto utilizamos o Plotlt e Dash. Entretanto, entregar eles para os usuários não é tão simples, pois requer um servidor on-line que requer investimento financeiro.
Contudo, utilizando o Google Colab esta barreira reduz, facilitando a entrega. Mas não se contrapartidas. Na fora utilizada aqui, o usuário ainda precisa ter contato com programação. Pouca coisa, mas precisa, o que é uma barreira. O ideal seria colocar o Dashboard on-line, mas falta investimento financeiro.