

Dashboards com Python (Parte 1)
Desenvolvendo gráficos com matplotlib, Plotly e Dash (Parte 1 de 3)!
Olá 😀!
Uma das ferramentas mais importantes na análise de dados é a visualização dos dados. Fazer a análise dos dados sem uma boa estrutura de visualização dos dados para auxílio, pode comprometer a análise e levar a conclusões equivocadas. Além disto, o design das visualizações também impacta na forma com que o leitor (seu chefe, superior, membro da banca, corretor do artigo, leitor, etc) vai perceber os resultados. Quanto mais fácil a interpretação, melhor.
Este texto tem como principal objetivo apresentar algumas possibilidades para a geração e apresentação de gráficos. São utilizadas três bibliotecas diferentes para gerar os gráficos (matplotlib, Plotly e Dash), onde basicamente é repetido o mesmo gráfico nas três bibliotecas. Mas acabou que o texto ficou um tanto longo, então eu dividi tudo em três partes (1- preparo dos dados + gráficos no matplotlib; 2 - gráficos no Plotly e; 3- Dashboards com Dash).
De qualquer forma, precisamos de dados para serem analisados. Ao invés de utilizar um conjunto de dados genérico (como o flor de Iris, ou um gerado com dados aleatórios), vou utilizar os dados do número de focos de queimadas nos biomas brasileiros. A escolha foi feita para simular um ambiente onde precisamos tratar os dados antes de desenhar os gráficos, pois esta é uma parte que muitas vezes fica de lado em tutoriais por aí, mas que é extremamente importante (tanto para obter melhores resultados como para auxiliar o leitor a entender os quês e os porquês daquilo que está sendo feito).
O que você irá ver neste estudo?
- Parte 1 - Gráficos com matplotlib;
- Parte 2 - Gráficos com Plotly;
- Introdução;
- Gráfico de dispersão com linhas;
- Gráfico de barras;
- Gráfico de pizza;
- Introdução;
- Parte 3 - Dashboards com Dash;
- Introdução;
- Dropdown;
- Gráfico de dispersão com linhas;
- Gráfico de barras;
- Gráfico de pizza;
- Ajustes finais;
- Conclusão.
- Introdução;
Ambiente de trabalho
Para desenvolver este exemplo eu utilizei a distribuição Anaconda do Python (3.7.3). Também utilizei a IDE Jupyter notebook (para desenvolver os códigos) e Atom (para fazer o deploy ao final do desenvolvimento). As principais bibliotecas utilizadas foram:
✔ Pandas, versão = 0.24.2 (para gerenciar os dados);
✔ matplotlib, versão = 3.1.1 (para gerar gráficos estáticos);
✔ NumPy, versão = 1.16.4 (vai que precisa);
✔ SciPy, versão = 1.3.0 (vai que precisa);
✔ Plotly, versão = 4.14.3 (para gerar gráficos interativos);
✔ Dash, versão = 1.19.0 (para gerar Dashboards interativos).
Aquisição de dados
Os dados foram coletados no site do INPE, tendo sido obtido os dados de focos de queimadas separados por biomas brasileiros, no dia 30/01/2021. Também temos dados separados por estados, mas estes ficam para uma outra oportunidade.
Os dados estão separados em arquivos “.csv” diferentes, mas todos tem o mesmo padrão, como você pode ver de forma exemplificada na imagem baixo:
Figura 1 - Exemplo de como o arquivo “csv” foi construído.
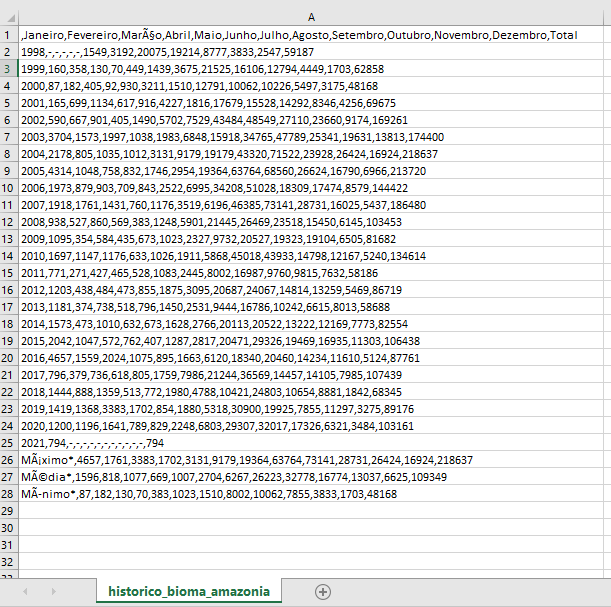
Algumas alterações são necessárias nestes arquivos. A primeira célula (A1) começa com uma vírgula, o que indica que a primeira coluna não tem nome. Como esta coluna é referente ao Ano, adiciono Ano antes desta primeira vírgula. Também observamos que as 3 últimas linhas correspondem aos valores mínimos, máximos e médios de cada mês, mas não precisamos destes dados (além de ser muito simples de obtê-los caso seja necessário). Então vou remover as linhas 26, 27 e 28. A linha 25 corresponde ao ano de 2021, e como hoje é dia 31/01/2021, os dados não estão consolidados nem do primeiro mês do ano, e por isso vou remover a linha 25 também. Dessa forma, temos dados dos 12 meses em todos os anos do período.
Repare que a não ser pelo nome do arquivo, não temos em lugar nenhum o nome do bioma nos dados. Então, vou adicionar uma nova coluna para referenciar o bioma que cada linha representa.
Observe também que temos alguns valores com um “-“, o que provavelmente corresponde a não ter sido identificado nenhum foco de queimada naquele mês. Não ter sido detectado nenhum foco não quer dizer que não teve nenhum foco, mas para o nosso caso aqui, eu vou admitir que não houve nenhum foco nestes meses. Então é preciso alterar o traço por um zero. Fazer isto é bem simples com o Pandas, então vou deixar os dados dessa forma por enquanto.
Agora basta fazer todas estas alterações em cada um dos arquivos .csv, e então junta-los em um único arquivo. Você pode baixar esse único arquivo aqui.
Checando os dados
Agora vamos verificar como estão os dados. Começamos importando as principais bibliotecas:
import pandas as pd
import numpy as np
import scipy.stats as stas
import matplotlib.pyplot as plt
E começo carregando os dados, o que podemos fazer utilizando o Pandas:
df = pd.read_csv('historico_bioma_completo.csv')
df.head()
Mas ao fazer isto, o carregamento falhou retornando um erro:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xe7 in position 3: invalid continuation byte
Este erro é bastante comum quando trabalhamos com dados que utilizam outras línguas que não o inglês. Provavelmente o problema está nos acentos, como o “^” de Amazônia, ou no “ç” de Março. Para contornar este problema, podemos adicionar o parâmetro encoding='latin-1' dentro de pd.read_csv():
df = pd.read_csv('historico_bioma_completo.csv', encoding='latin-1')
df.head()
Figura 2 - DataFrame contendo dos dados de focos de queima nos biomas brasileiros.
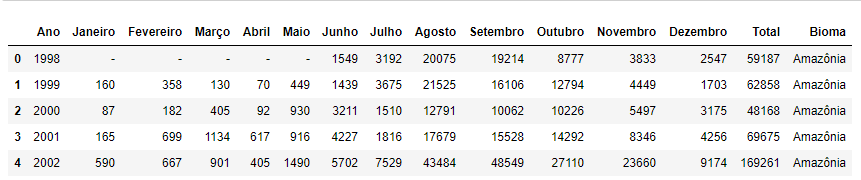
Aparentemente está tudo correto. Vamos começar substituindo o “-“ pelo número 0, o que podemos fazer utilizando o método replace() dos DataFrames:
df.replace('-',0, inplace=True)
df.head()
Figura 3 - Imagem do DataFrame após substituição do traço pelo zero.

Agora vamos verificar como estão estes dados, pedindo as informações gerais do DataFrame:
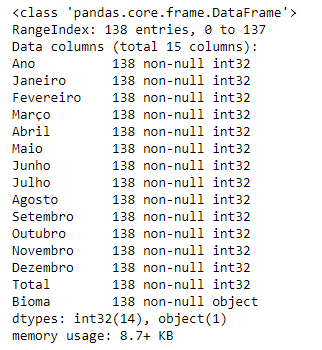
df.info()
Figura 4 - Informações gerais do DataFrame.
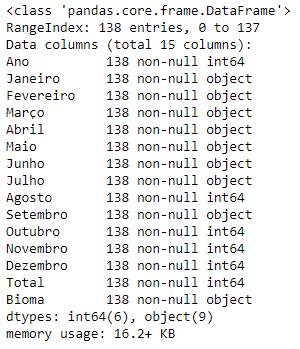
Temos 138 entradas, subdivididas entres o biomas como esperado, mas chama a atenção o tipo de dados nas colunas. Com exceção das colunas “Ano”, “Agosto”, “Outubro”, “Novembro”, “Dezembro” e “Total”, que são números inteiros, as demais colunas estão como tipo objeto, o que é estranho pois deveriam ser números inteiros (com exceção da coluna Bioma, que poderia ser um objeto).
Uma forma indireta de verificar o tipo de dado das colunas é utilizar o método describe() dos DataFrames, que retorna uma série de estatísticas das colunas que apresentam valores numéricos:
df.describe()
Figura 5 - Imagem do resultado obtido ao calcular as estatísticas básicas das colunas numéricas do DataFrame.
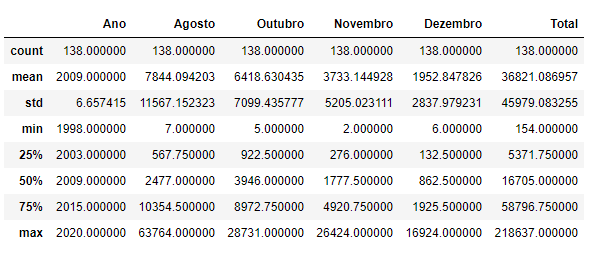
Como podemos observar, apenas as colunas “Ano”, “Agosto”, “Outubro”, “Novembro”, “Dezembro” e “Total”, tiveram suas estatísticas calculadas, o que significa que as demais colunas tem valores que não são numéricos. Então vamos verificar o tipo de dado de cada célula do DataFrame.
Provavelmente existe uma forma pythonica de fazer isto, mas eu desconheço. Então, vou varrer célula por célula ao longo das colunas e solicitar para imprimir o resultado do tipo de dado que cada célula contém:
colunas = list(df.columns) # armazenando o nome das colunas em uma variável
for j in range(df.shape[1]): # loop para iterar ao longo das colunas
print(colunas[j]) # printar o nome da coluna
for i in range(10): # Loop para iterar nas 10 primeiras linhas
print(type(df[colunas[j]][i])) # printando o tipo de cada célula
Figura 6 - Tipo da variável contida cada célula do DataFrame, focado no mês de Janeiro.
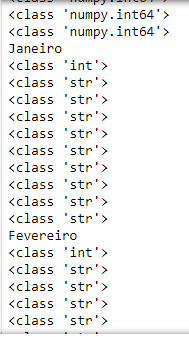
Como podemos verificar através do mês de Janeiro, as células são na sua maioria do tipo string, e não do tipo int como precisamos. Na verdade, temos uma mistura de células de string e de células do tipo int, onde provavelmente as células int são as células onde o traço foi substituído pelo número zero quando utilizei o método replace().
Então precisamos converter estas strings para int para poder desenhar os gráficos. Para fazer isto, podemos iterar ao longo das colunas e utilizar o método astype(int) nas colunas que devem ser numéricas:
for j in range(df.shape[1]-1): # loop para iterar ao longo das colunas. O menos 1 é para não dar problema com as strings da ultima coluna
df[colunas[j]] = df[colunas[j]].astype(int) # trocando o valor de str para int
Para conferir, vou utilizar o método info() novamente:
Figura 7 - Informações gerais do DataFrame após mudança no tipo de dados das células.
Agora sim temos todas as colunas (exceção da coluna Bioma) com valores numéricos e podemos começar a desenhar os gráficos.
Mas antes disso, eu vou criar um novo arquivo “.csv” e salvar este DataFrame neste arquivo, pois foram feitas muitas alterações nos dados, e é melhor ter um arquivo pronto para ser utilizado, do que ter de ficar fazendo os ajustes nos dados todas as vezes que for mexer com o conjunto de dados.
df.to_csv('biomas_dados_historicos.csv', encoding='latin-1', index=False)
Agora basta recarregar novamente o data frame (com o novo arquivo) e podemos seguir.
df = pd.read_csv('biomas_dados_historicos.csv', encoding='latin-1')
Gráficos com matplotlib
Eu vou começar a desenhar gráficos com o matplotlib pois é bem simples de ser feito, e vai fornecer bagagem para refazer os gráficos no Plolty e depois no Dash. Uma das vantagens do matplotlib é a diversidade em formatos que podemos exportar os gráficos gerados, variando do “.png” e “.jpg”, passando pelo “.pdf” e indo até “.tif”.
Vou desenhar 3 gráficos:
- Gráfico de dispersão com linhas: Neste gráfico eu vou correlacionar os meses (no eixo x) com o número de focos de queimadas correspondentes a cada ano (eixo y). Primeiro vou fazer para um único ano, depois expandir para todos os anos, e finalmente gerar um gráfico para cada bioma;
- Gráfico de barras: Neste gráfico vou correlacionar os anos (eixo x) com o total acumulado no ano correspondente (eixo y);
- Gráfico de pizza: No gráfico de pizza vamos comparar a proporção de focos de queimadas ao longo dos anos avaliados para cada bioma.
Gráfico de dispersão com linhas
Para gerar um gráfico de dispersão com linhas, precisamos apenas dos valores de x e dos valores de y. No eixo x vamos ter os meses, que podemos obter diretamente do nome das colunas:
x = df.columns.values[1:13]
No eixo y vamos ter o número de focos de queimadas por mês, dado este que está nas colunas. Entretanto, como temos vários biomas, precisamos filtrar os valores de y baseado na coluna “Bioma”, afim de acessar os dados corretos. Então eu vou criar um novo data frame com os dados filtrados para um único bioma, que eu vou escolher como o bioma Amazônia:
df_aux = df[df['Bioma'] == 'Amazônia']
Para acessar os dados nas linhas podemos utilizar o loc, passando a linha correspondente e o intervalo de colunas desenhados. Vamos começar com o primeiro ano que esta na posição 0, e o intervalo que nos interessa está entre as colunas 1 e 12 (a coluna 0 contém o ano, a coluna 13 contém o total de focos e a coluna 14 contém o nome do bioma).
y = df_aux.loc[0][1:13]
Agora que temos os valores de x e y, basta criar o gráfico:
plt.figure(figsize=(12,6)) # criando o canvas com um tamanho pré-determinado
plt.plot(df.columns.values[1:13], # valores de x
df_aux.loc[0][1:13], # valores de y, para apenas o primeiro ano
label = str(df.loc[0][0]), # nome do ano para a legenda (precisa ser transformado em string)
marker = 'o') # para que o ponto seja apresentado é necessário passar o marker com o simbolo do marcador
plt.xlabel("Meses") # nome do eixo x
plt.ylabel("Número de focos de queimadas") # nome do eixo y
plt.title("Número de focos de queimadas identificados no bioma: " + str(df.loc[0][14])) # Titulo do gráfico
plt.legend() # adicionar a legenda
plt.show() # apresentar o gráfico
Figura 8 - Gráfico de dispersão com linhas do Bioma Amazônia no ano de 1988.
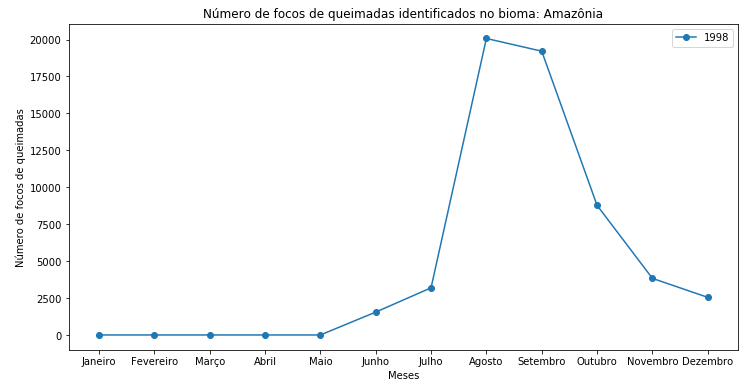
Mas este gráfico tem apenas os dados de um único ano. Para adicionar os demais anos da série, precisamos iterar ao longo de todos os anos, adicionando um ano após o outro. Para fazer isto, vou substituir onde temos o 0 por um “i” para poder iterar ao longo das linhas. Então, vou colocar todo o código dentro de um loop for, e fazer com que ele percorra todas as linhas do df_aux.
plt.figure(figsize=(12,6)) # criando o canvas com um tamanho pré-determinado
for i in range(df_aux.shape[0]): # percorrendo todos os anos
plt.plot(df_aux.columns.values[1:13], # valores de x, alterado para o df_aux
df_aux.loc[i][1:13], # valores de y, para apenas o primeiro ano
label = str(df.loc[i][0]), # nome do ano para a legenda (precisa ser transformado em string)
marker = 'o') # para que o ponto seja apresentado é necessário passar o marker com o simbolo do marcador
plt.xlabel("Meses") # nome do eixo x
plt.ylabel("Número de focos de queimadas") # nome do eixo y
plt.title("Número de focos de queimadas identificados no bioma: " + str(df.loc[0][14])) # Titulo do gráfico
plt.legend() # adicionar a legenda
plt.show() # apresentar o gráfico
Figura 9 - Gráfico de dispersão com linhas para o Bioma Amazônia em todo o período.
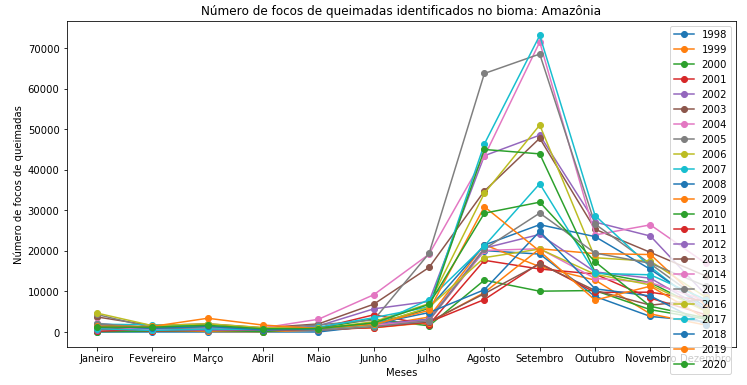
Mas repare que a legenda acabou sobrepondo os dados. Para resolver este problema, eu vou colocar a legenda ao lado direito do gráfico (lado de fora). Para isto, basta passar o parâmetro bbox_to_anchor() para o legend(), com uma tupla indicando a posição da legenda:
plt.legend(bbox_to_anchor = (1.02,1.05))
Figura 10 - Gráfico de dispersão com linhas para o Bioma Amazônia em todo o período com legendas ajustadas.
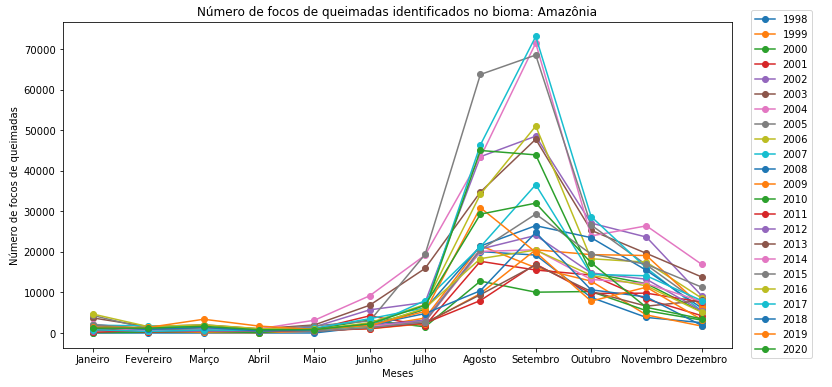
Agora falta gerar os gráficos para os demais biomas. Para isto, basta colocar todo o código em um novo for loop, e iterar ao longo dos diferentes tipos de biomas:
for j in range(len(df['Bioma'].unique())):# percorrendo todos os biomas
df_aux = df[df['Bioma'] == df['Bioma'].unique()[j]] # redefinindo do df_aux para o bioma
df_aux.reset_index(drop=True, inplace=True) # redefinindo o indice
plt.figure(figsize=(12,6)) # criando o canvas com um tamanho pré-determinado
for i in range(df_aux.shape[0]): # percorrendo todos os anos
plt.plot(df_aux.columns.values[1:13], # valores de x, alterado para o df_aux
df_aux.loc[i][1:13], # valores de y, para apenas o primeiro ano
label = str(df_aux.loc[i][0]), # nome do ano para a legenda (precisa ser transformado em string)
marker = 'o') # para que o ponto seja apresentado é necessário passar o marker com o simbolo do marcador
plt.xlabel("Meses") # nome do eixo x
plt.ylabel("Número de focos de queimadas") # nome do eixo y
plt.title("Número de focos de queimadas identificados no bioma: " + str(df_aux.loc[0][14])) # Titulo do gráfico
plt.legend(bbox_to_anchor = (1.02,1.05)) # adicionar a legenda
plt.show() # apresentar o gráfico
Figura 11 - Gráfico de dispersão com linhas para os diferentes bioma brasileiros em todo o período.
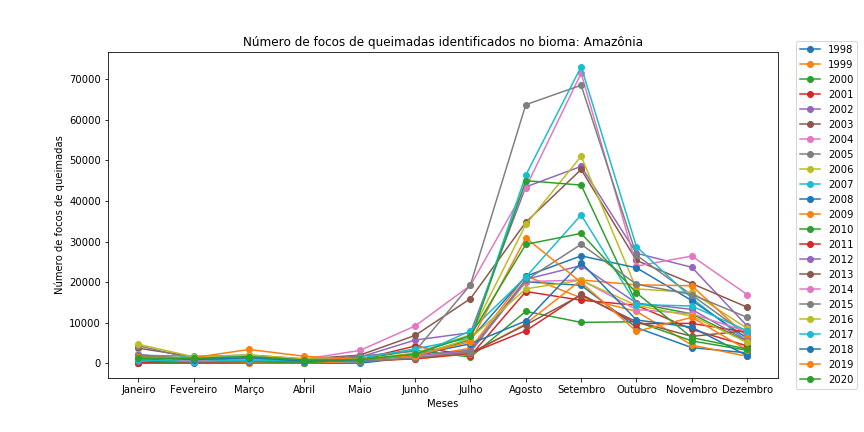
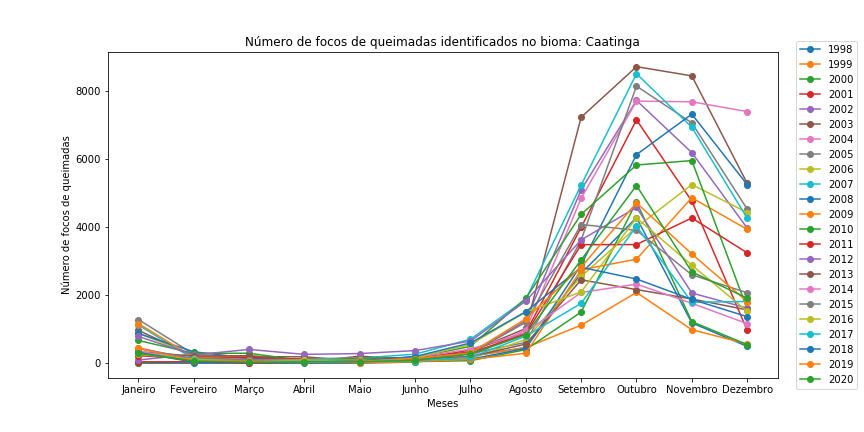
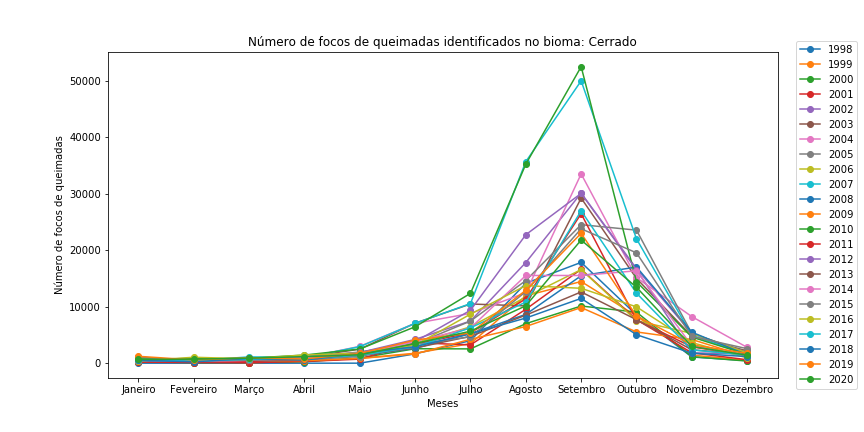
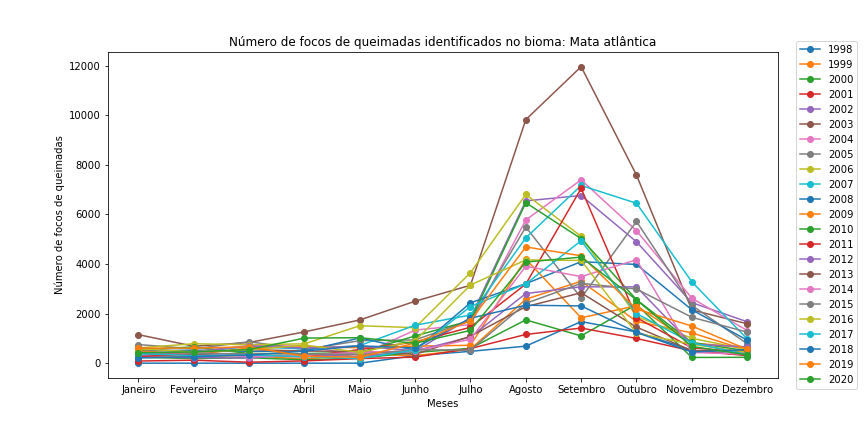
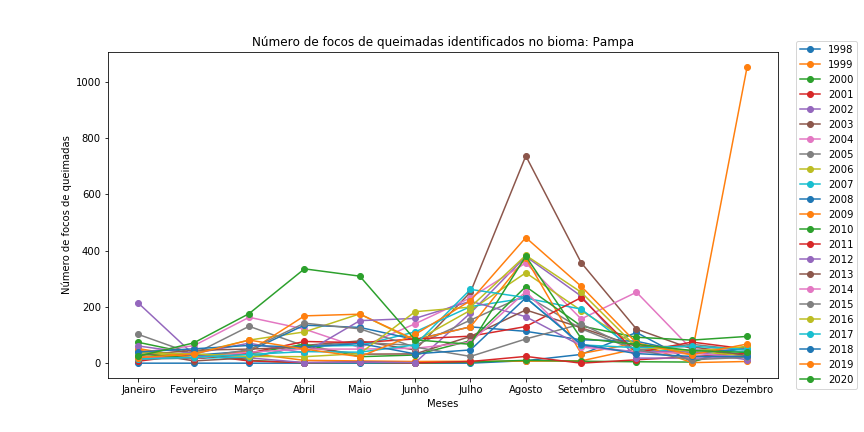
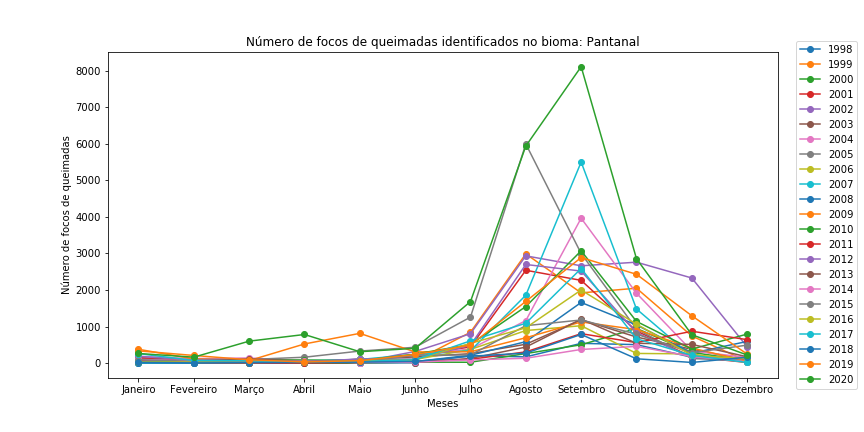
Observe que é necessário redefinir o df_aux a cada iteração de bioma, bem como resetar o índice do df_aux, pois assim evitamos problemas com o loc.
Gráfico de barras
Para gerar o gráfico de barras, basta passar os dados do eixo x (que nesse caso são os anos), e os dados do eixo y (que neste caso é o total de focos de queimadas).
df_aux = df[df['Bioma'] == 'Amazônia']
plt.figure(figsize=(12,6))
plt.bar(df_aux['Ano'],
df_aux['Total'])
plt.show()
Figura 12 - Gráfico de barras para o total de focos de queimada por ano no bioma Amazônia.
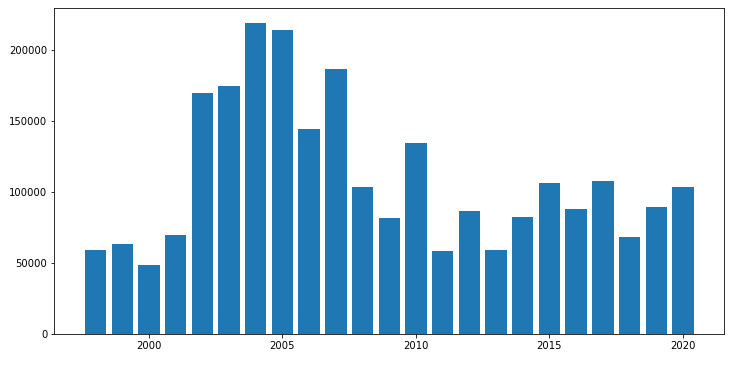
Mas repare que o eixo x não está com os labels em todos os anos. Para adicionar, é necessário passar explicitamente os valores dos ticks através de plt.xticks(df_aux['Ano']). Vou aproveitar e adicionar titulo e nome nos eixos.
df_aux = df[df['Bioma'] == 'Amazônia']
plt.figure(figsize=(12,6)) # Criando a figura
plt.bar(df_aux['Ano'], # dados eixo x
df_aux['Total']) # dados eixo y
plt.xlabel("Anos") # legenda no eixo x
plt.ylabel("Número de focos de queimadas totais") # legenda no eixo y
plt.title("Variação do número total de focos de queimadas identificados no bioma " + df_aux['Bioma'][0]) # titulo
plt.xticks(df_aux['Ano'], rotation = 45) # alterando os ticks para que todos os anos sejam apresentados e girando um pouco o ticks
plt.show()
Figura 13 - Gráfico de barras editado para o total de focos de queimada por ano no bioma Amazônia.
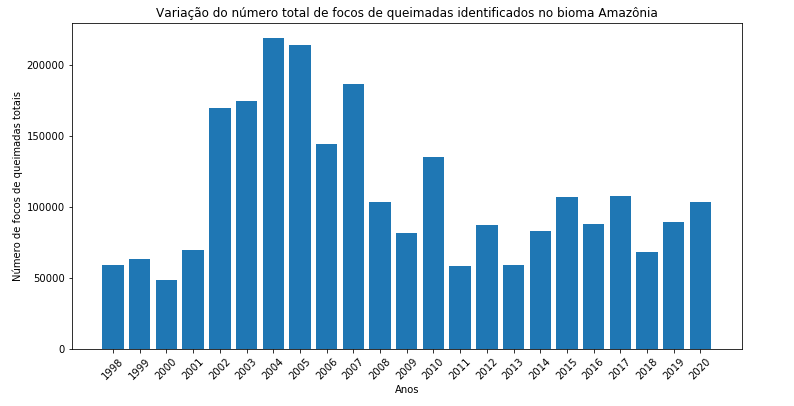
Agora vou desenhar um gráfico de barras para cada Bioma, para facilitar a visualização do comportamento dos focos de queimadas ao longo das últimas duas décadas. Para fazer isto, basta colocar o código em um loop for e iterar ao longo dos diferentes tipos de biomas:
for j in range(len(df['Bioma'].unique())):# percorrendo todos os biomas
df_aux = df[df['Bioma'] == df['Bioma'].unique()[j]] # redefinindo do df_aux para o bioma
df_aux.reset_index(drop=True, inplace=True) # redefinindo o indice
plt.figure(figsize=(12,6)) # Criando a figura
plt.bar(df_aux['Ano'], # dados eixo x
df_aux['Total']) # dados eixo y
plt.xlabel("Anos") # legenda no eixo x
plt.ylabel("Número de focos de queimadas totais") # legenda no eixo y
plt.title("Variação do número total de focos de queimadas identificados no bioma " + df_aux['Bioma'][0]) # titulo
plt.xticks(df_aux['Ano'], rotation = 45) # alterando os ticks para que todos os anos sejam apresentados e girando um pouco o ticks
plt.show()
Figura 14 - Gráfico de barras para o total de focos de queimada por ano nos diferentes biomas brasileiros.
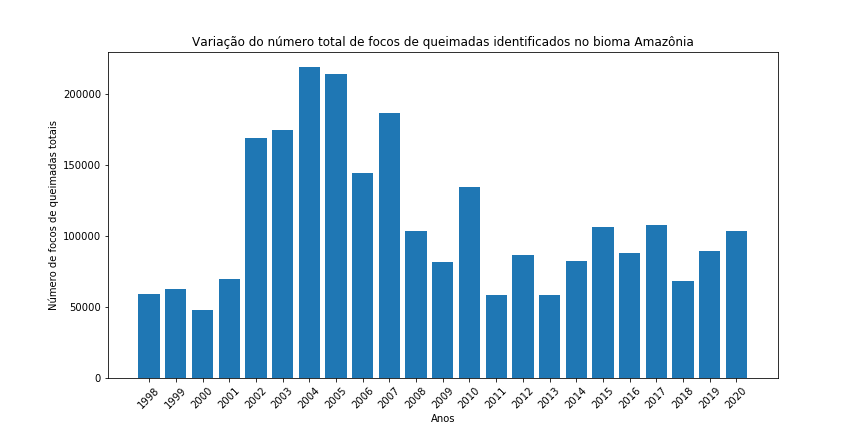
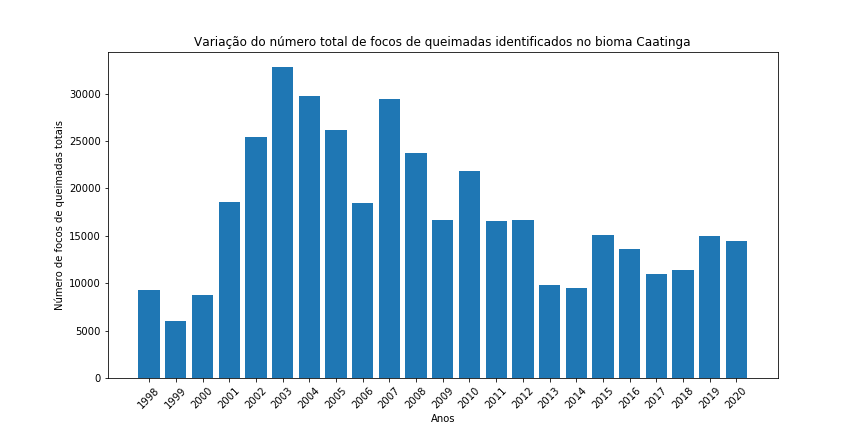
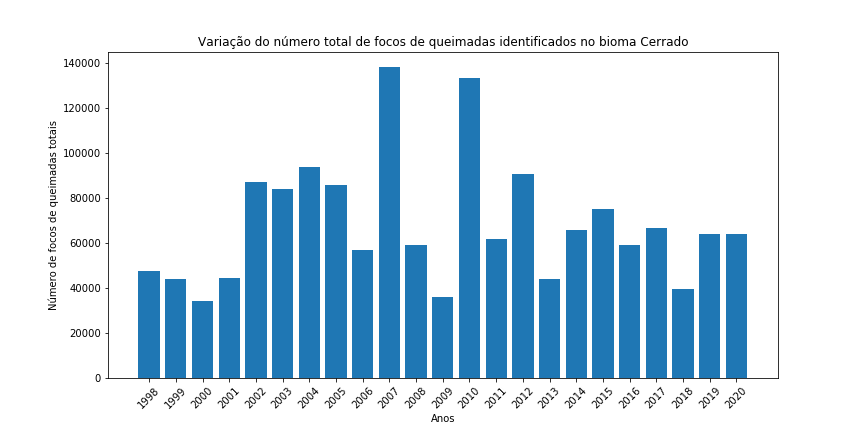
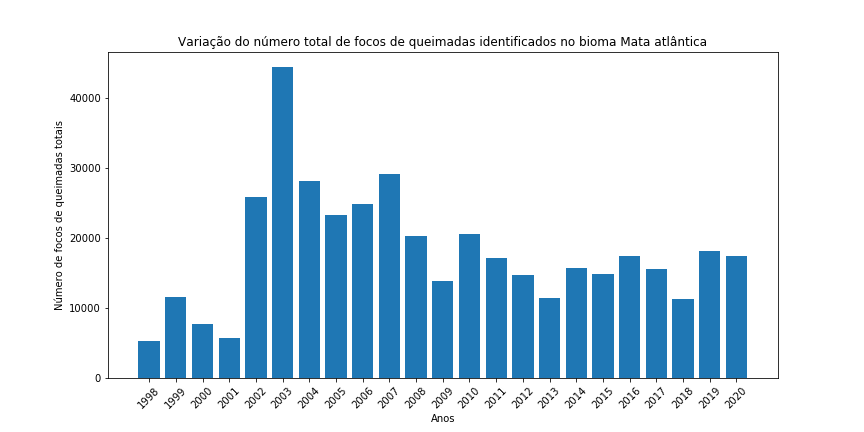
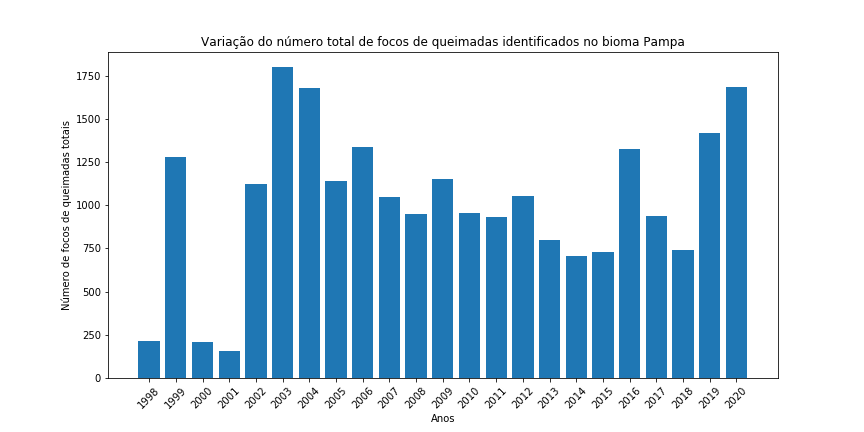
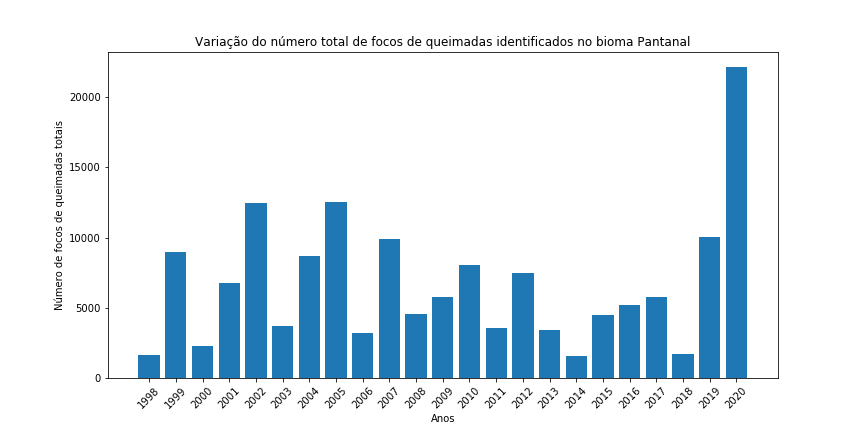
Gráfico de pizza
Gráficos de pizza não são muito comuns de serem utilizados neste tipo de dado, entretanto, eles fornecem de forma visual a porcentagem que cada dado contribui para o todo, o que pode ser realmente útil em alguns casos.
Para gerar um gráfico de pizza, basta passar os valores de x (o número total de focos neste caso) e os respectivos labels (o ano neste caso).
df_aux = df[df['Bioma'] == 'Amazônia']
plt.figure(figsize=(8,8))
plt.pie(x = df_aux['Total'],
labels = df_aux['Ano'],)
plt.show()
Figura 15 - Gráfico de pizza para comparação entre o total de focos de queimadas identificados a cada ano.
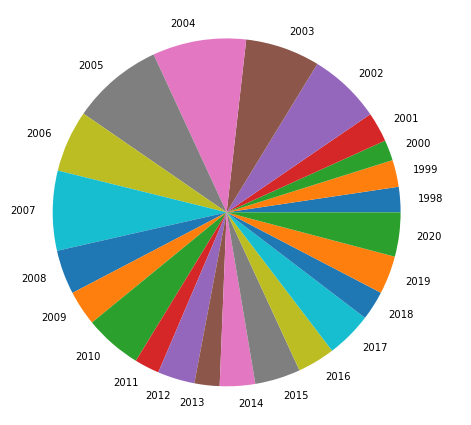
Mas esta forma não é muito atraente, então vou editar um pouco. Um gráfico de pizza geralmente traz as fatias ordenadas da maior para a menor, o que facilita a visualização do padrão.
Geralmente, ordenar dados é bem simples (através do método sort()), mas neste caso é preciso ordenar do maior para o menor número de focos de queimadas, mas mantendo o label correto. A priori isto parece complicado, mas com a função zip(), reordenar os dois conjuntos ao mesmo tempo (mantendo o par correto) fica menos difícil:
df_aux = df[df['Bioma'] == 'Amazônia']
x, y = zip(*sorted(zip(df_aux['Total'], df_aux['Ano']),reverse=True)) # ordenando os dados do maior para o menor
plt.figure(figsize=(8,8))
plt.pie(x = x,
labels = y,)
plt.show()
Figura 16 - Gráfico de pizza ordenado para comparação entre o total de focos de queimadas identificados a cada ano.
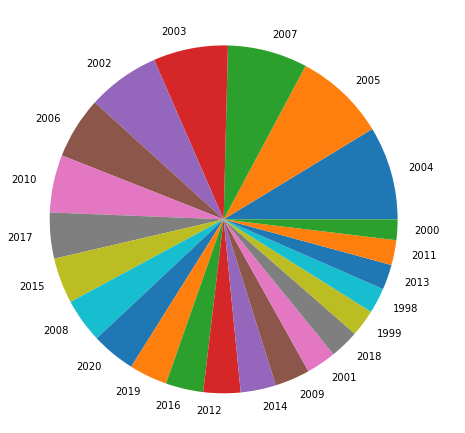
Mas as cores não estão boas, e é necessário alterar. Poderíamos escolher cores específicas para cada fatia da pizza, mas eu prefiro utilizar um colormap do próprio matplotlib, pois é muito mais simples. Eu vou utilizar o colormap tab20c.colors pois ele tem cores suaves.
Outra coisa interessante em se alterar é o ângulo em que as fatias começam a serem colocadas. Por padrão, o matplotlib inicia em 0° (plano cartesiano) e vai preenchendo no sentido anti-horário. Eu prefiro iniciar em 90°, mas mantendo o sentido anti-horário. Para alterar esta posição de inicio para 90°, basta passar o parâmetro startangle = 90.
from matplotlib import cm
df_aux = df[df['Bioma'] == 'Amazônia']
x, y = zip(*sorted(zip(df_aux['Total'], df_aux['Ano']),reverse=True)) # ordenando os dados do maior para o menor
plt.figure(figsize=(8,8))
plt.pie(x = x,
labels = y,
colors=cm.tab20c.colors,
startangle=90,
)
plt.show()
Figura 17 - Comparação entre o total de focos de queimadas ao logo de cada ano avaliado através do gráfico de pizza ordenado.
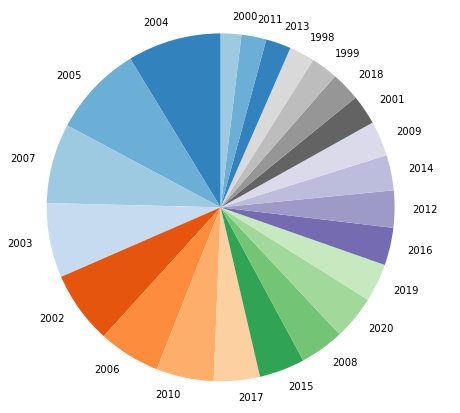
Também podemos adicionar a porcentagem que cada fatia contribui para a pizza inteira, o que ajuda muito na interpretação visual. Fazemos isto passando o parâmetro autopct = '%1.1f%%', que vai adicionar dentro de cada fatia a sua respectiva porcentagem.
Eu vou aproveitar e adicionar o comando plt.tight_layout(), que vai deixar o gráfico mais justo.
df_aux = df[df['Bioma'] == 'Amazônia']
x, y = zip(*sorted(zip(df_aux['Total'], df_aux['Ano']),reverse=True)) # ordenando os dados do maior para o menor
plt.figure(figsize=(8,8))
plt.pie(x = x,
labels = y,
colors=cm.tab20c.colors,
startangle=90,
autopct='%1.1f%%',
)
plt.tight_layout()
plt.show()
Figura 18 - Comparação entre o total de focos de queimadas ao logo de cada ano avaliado através do gráfico de pizza ordenado.
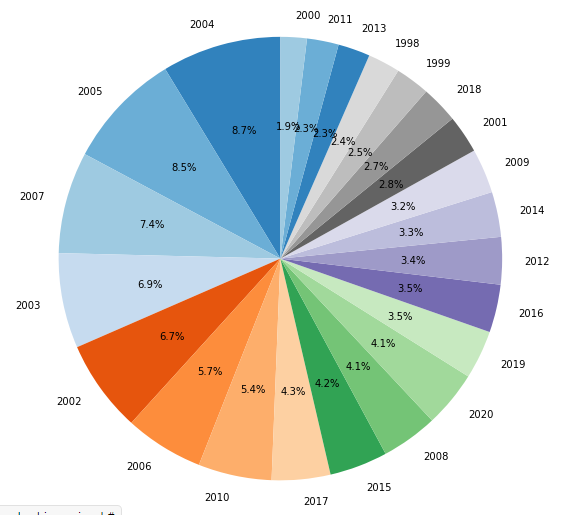
Uma outra coisa interessante a se fazer é adicionar o parâmetro explode. Este parâmetro é uma forma de “puxar” a fatia um pouco para fora da pizza, para realçar alguma coisa. Ele precisa ser uma lista com o mesmo número de fatias. Eu gosto de adicionar essa “puxada” em fatias de número primo.
df_aux = df[df['Bioma'] == 'Amazônia']
x, y = zip(*sorted(zip(df_aux['Total'], df_aux['Ano']),reverse=True)) # ordenando os dados do maior para o menor
plt.figure(figsize=(8,8))
plt.pie(x = x,
labels = y,
colors=cm.tab20c.colors,
startangle=90,
autopct='%1.1f%%',
explode = [0, 0, 0.02, 0.03, 0, 0.035, 0, 0.040, 0, 0, 0, 0.045, 0, 0.05, 0, 0, 0, 0.060, 0, 0.065, 0, 0, 0])
plt.tight_layout()
plt.show()
Figura 19 - Gráfico de pizza ordenado e editado comparando o total de focos de queimadas ao longo de cada ano avaliado.
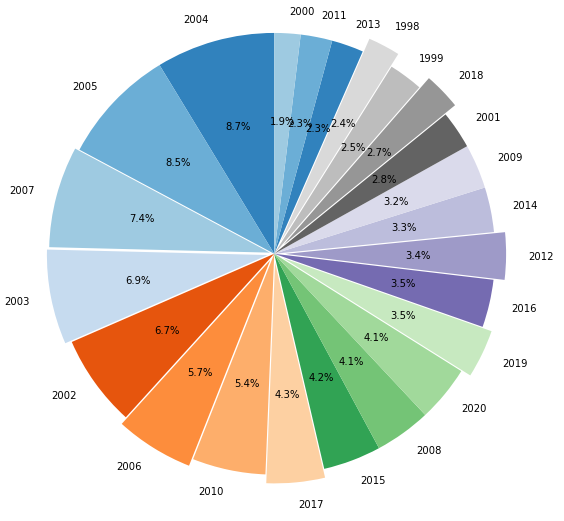
Agora falta apenas adicionar um título e desenhar o gráfico para os outros biomas. Para os novos desenhos, basta colocar todo o código em um loop for e iterar através dos diferentes biomas:
for j in range(len(df['Bioma'].unique())):# percorrendo todos os biomas
df_aux = df[df['Bioma'] == df['Bioma'].unique()[j]]
x, y = zip(*sorted(zip(df_aux['Total'], df_aux['Ano']),reverse=True)) # ordenando os dados do maior para o menor
plt.figure(figsize=(8,8))
plt.pie(x = x,
labels = y,
colors=cm.tab20c.colors,
startangle=90,
autopct='%1.1f%%',
explode = [0, 0, 0.02, 0.03, 0, 0.035, 0, 0.040, 0, 0, 0, 0.045, 0, 0.05, 0, 0, 0, 0.060, 0, 0.065, 0, 0, 0])
plt.title("Comparativo entre o total de focos de queimadas identificados por ano ano bioma: " + df['Bioma'].unique()[j])
plt.tight_layout()
plt.show()
Figura 20 - Gráfico de pizza comparando o total de focos de queimadas ao longo de cada ano avaliado nos diversos biomas brasileiros.
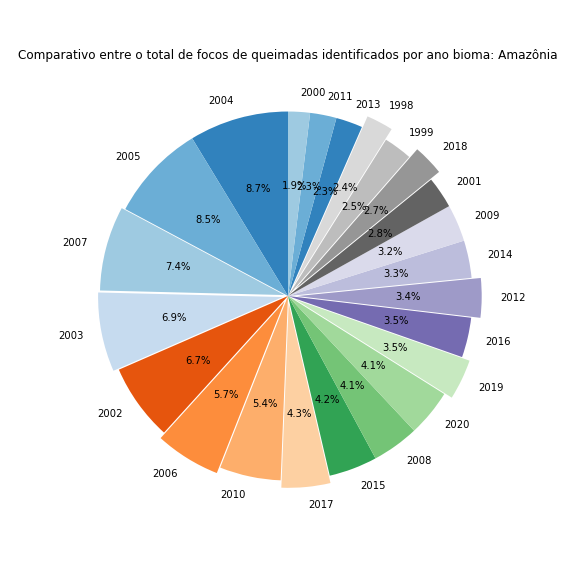
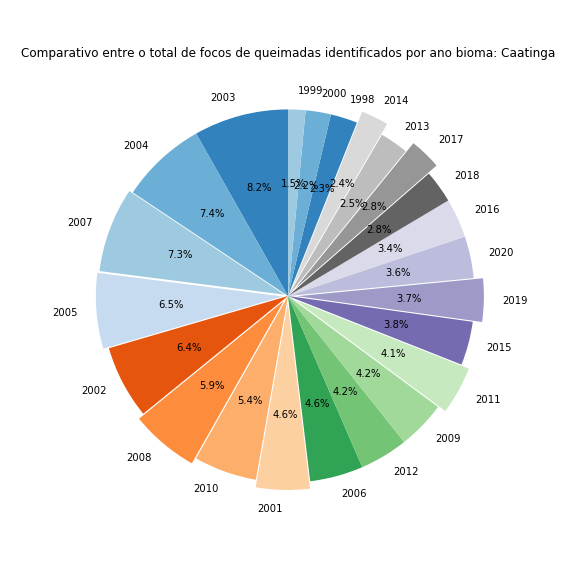
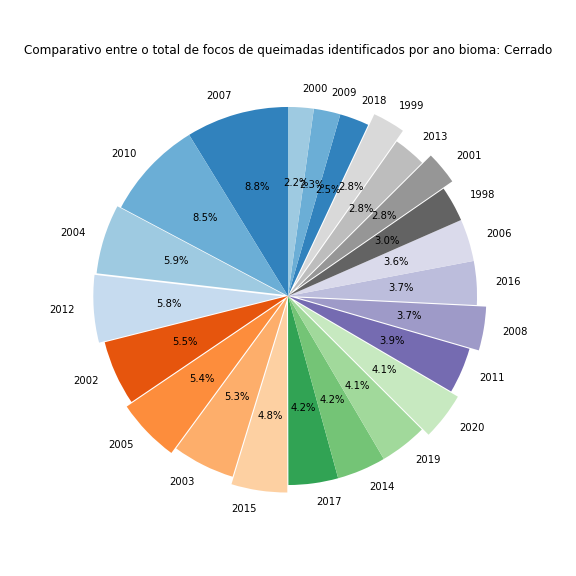
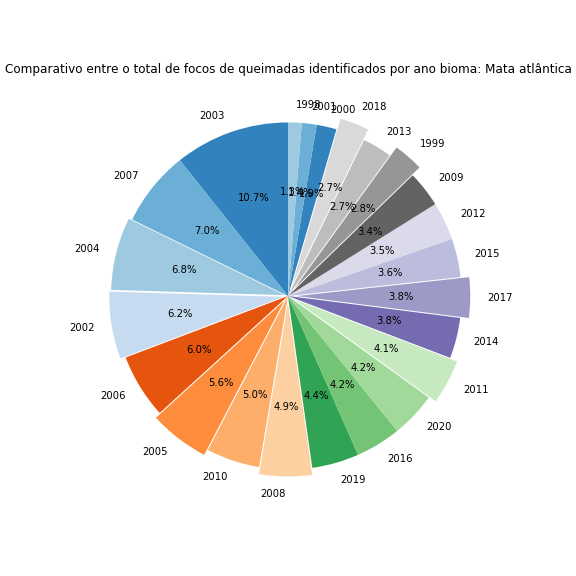
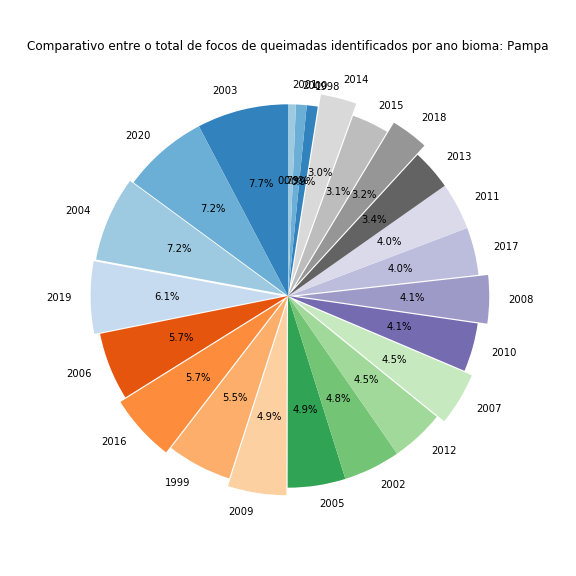
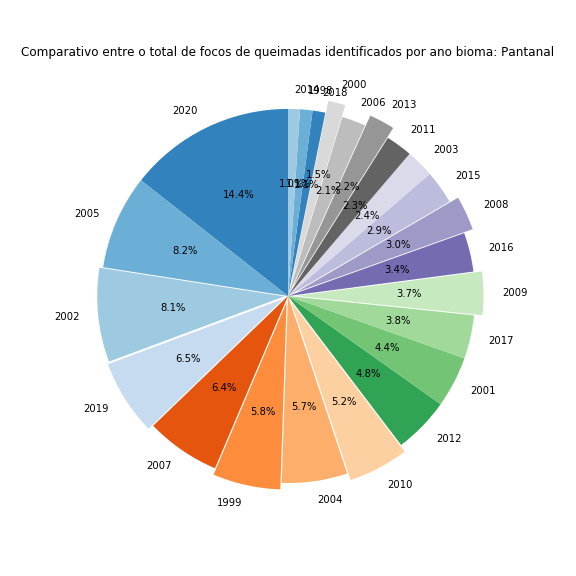
Com isso finalizo a geração de dados com matplotlib. É sempre uma aventura divertida brincar com essa biblioteca 😃.
Você pode baixar o notebook construído até aqui neste link.
Na Parte 2 vamos gerar os mesmos gráficos, mas agora utilizando o Plotly. Te vejo lá 💪!